I Cut My OpenClaw Costs by 97%
摘要
OpenClaw 是一個可本地部署的 AI 個人助理平台,但其預設配置會造成嚴重的 token 浪費。作者透過四個優化步驟,將成本從每月 $70-90 降至 $3-5,並讓複雜的隔夜任務(14 個 sub-agent 跑 6 小時)只花 $6。核心觀點:AI agent 的預設配置優先考慮能力而非成本,使用者必須主動介入優化。
重點筆記
Part 1: Session Initialization — 停止每次載入 50KB 歷史
OpenClaw 的核心架構問題:每次訊息(包含心跳)都會載入全部 context files + session history。 隨著使用時間增長,context 從 50KB 膨脹到 75KB、100KB 甚至更大。作者透過 Slack 溝通時,發現系統把所有 Slack 歷史訊息(111KB 純文字)也一併送出。
解法:只在啟動時載入必要檔案,其餘按需載入。
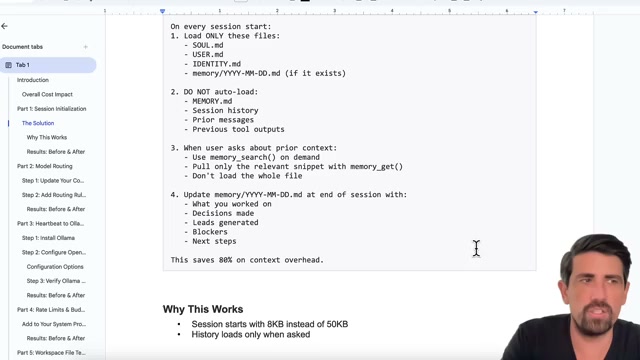
具體策略:
- 啟動時只載入:
SOUL.md、USER.md、IDENTITY.md、memory/YYYY-MM-DD.md - 不自動載入:
MEMORY.md、Session history、Prior messages、Previous tool outputs - 需要歷史時用
memory_search()按需查詢 - 建立
new session指令清除 Slack session history,但保留重點到 memory
這一步就節省了 80% 的 context 開銷。
Part 2: Model Routing — 多模型分層路由
不要只用一個模型做所有事。 設定 config 讓不同複雜度的任務使用不同模型。
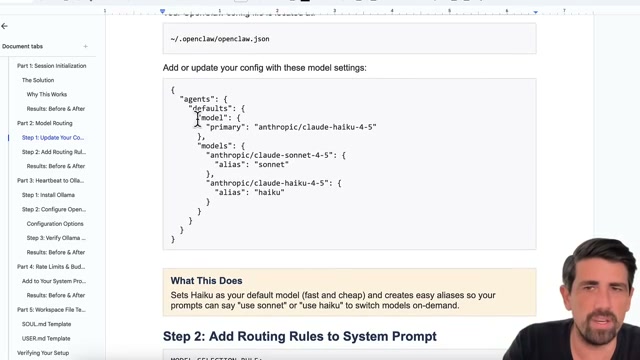
設定檔 ~/.openclaw/openclaw.json:
{
"agents": {
"defaults": {
"model": {
"primary": "anthropic/claude-haiku-4-5"
},
"models": {
"anthropic/claude-sonnet-4-5": {
"alias": "sonnet"
},
"anthropic/claude-haiku-4-5": {
"alias": "haiku"
}
}
}
}
}在 System Prompt 中加入路由規則:
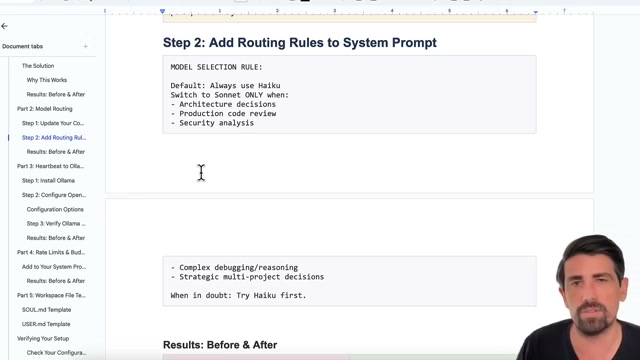
MODEL SELECTION RULE:
Default: Always use Haiku
Switch to Sonnet ONLY when:
- Architecture decisions
- Production code review
- Security analysis
- Complex debugging/reasoning
- Strategic multi-project decisions
When in doubt: Try Haiku first.
路由結果的前後對比:
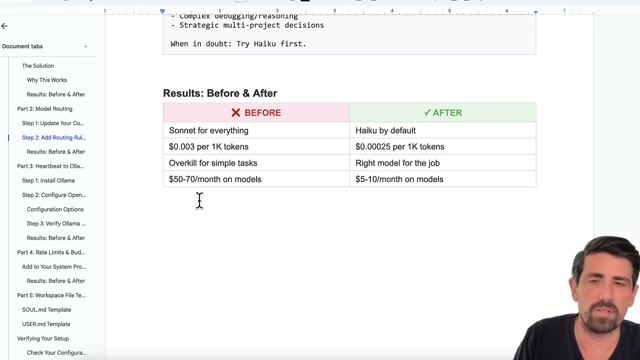
| 指標 | Before | After |
|---|---|---|
| 模型 | Sonnet for everything | Haiku by default |
| 每 1K tokens 成本 | $0.003 | $0.00025 |
| 月費 | $50-70 | $5-10 |
Part 3: Heartbeat to Ollama — 心跳改用免費本地 LLM
心跳只是檢查記憶體和任務狀態,不需要付費 API。 安裝 Ollama 並用 llama3.2:3b(2GB,輕量快速)處理心跳。
安裝:
# macOS / Linux
curl -fsSL https://ollama.ai/install.sh | sh
# 拉取輕量模型
ollama pull llama3.2:3bHeartbeat 設定:

{
"heartbeat": {
"every": "1h",
"model": "ollama/llama3.2:3b",
"session": "main",
"target": "slack",
"prompt": "Check: Any blockers, opportunities, or progress updates needed?"
}
}Part 4: Rate Limits & Budget Controls — 防止失控燒錢

在 System Prompt 中加入速率限制:
RATE LIMITS:
- 5 seconds minimum between API calls
- 10 seconds between web searches
- Max 5 searches per batch, then 2-minute break
- Batch similar work (one request for 10 leads, not 10 requests)
- If you hit 429 error: STOP, wait 5 minutes, retry
DAILY BUDGET: $5 (warning at 75%)
MONTHLY BUDGET: $200 (warning at 75%)
| Limit | 防止什麼 |
|---|---|
| 5s between API calls | 快速連續請求燒 token |
| 10s between searches | 昂貴的搜尋迴圈 |
| 5 searches max, then break | 失控的研究任務 |
| Batch similar work | 本來 1 次能做完的事做 10 次 |
Part 5: Workspace 檔案模板 — Keep It Lean

SOUL.md:定義 agent 核心原則和操作規則,包含 Model Selection 和 Rate Limits 摘要。
USER.md:提供使用者背景資訊和目標,包含 Success Metrics。
關鍵提醒:「Resist the urge to add everything to these files. Every line costs tokens on every request. Include only what the agent absolutely needs to make good decisions.」
整體成本影響

| 時間維度 | Before | After |
|---|---|---|
| Daily | $2-3 | $0.10 |
| Monthly | $70-90 | $3-5 |
| Yearly | $800+ | $40-60 |
實際應用案例
作者讓 OpenClaw 跑了一整夜的 B2B 業務開發任務:
- 14 個 sub-agent 同時運行
- Haiku:爬取網站、閱讀部落格、尋找目標企業
- Sonnet:撰寫 cold outreach 信件和 follow-up
- Ollama:整理檔案、組織 CSV
- 6 小時,$6(約 $1/小時)
- 同樣任務如果全用 Opus 大約要 $150
Token 審計與校準
- 在 Success Metrics 中加入「低 token 使用量」目標
- 每次任務前要求 AI 預估 token 消耗
- 任務完成後截圖 Anthropic dashboard 的實際用量餵回給 AI
- 做 3 次校準後達到 99% 預測準確度
- Caching 也很關鍵:有一次 95% 的 token 都是走 cached,大幅降低成本
我的想法
- 這個多模型路由的思路可以類推到 Claude Code 的使用:不需要每個任務都用 Opus,簡單任務用 Haiku 即可
- 「每次載入都有成本」的概念值得內化 — 適用於所有 context window 管理的場景
- Keep It Lean 原則很重要:context 檔案中的每一行在每次請求時都會消耗 token
- Token 審計 + 成本預測校準的循環方法論值得學習